

项目地址
GitHub
Gitee
项目描述
项目整体采用单Reactor多线程这一网络编程模型,其中主线程负责通过IO多路复用监听各个文件描述符,并处理连接的建立和断开 ,以及维护监听的文件描述符列表,当监听的文件描述符产生事件时,将文件描述符的读写以及具体事务逻辑提交到线程池的任务队列,由线程池中的子线程异步处理。当接收到HTTP Request报文时,使用有限状态机进行解析,并根据请求类型生成HTTP Response报文回复。另外还利用RAII机制实现了数据库连接池可以用于用户的注册和登录。并且还具有一个高性能的异步日志库可以实时输出程序运行过程中的信息。
项目功能
使用IO多路复用技术和线程池实现多线程的Reactor高并发模型;
使用标准库容器封装应用层动态扩容的缓冲区;
基于小根堆实现实现定时器,防止资源被长连接长时间霸占;
使用有限状态机解析HTTP报文,实现支持HTTP GET请求和POST请求;
使用双缓冲技术实现高性能异步日志库;
实现了数据库连接池,并利用RAII机制封装,在降低连接数据库开销的同时实现优雅获取与释放数据库连接;
实现更通用的POST请求;
使用更合适的设计模式改善程序的结构和可扩展性;
进一步抽象数据库连接池以扩展使用其他数据库。
项目解析
Buffer的设计
为什么需要应用层缓冲区?在解释这个问题之前,需要先说明本项目使用的Reactor模式的本质是“IO多路复用(IO multiplexing)+非阻塞IO(non-blocking)”的模式。为什么需要使用非阻塞IO?在实际应用中,IO多路复用和非阻塞IO往往一起搭配使用,原因有两点:
如果用轮训来检查某个非阻塞IO操作是否完成的话,太浪费CPU周期,所以需要搭配IO多路复用。
IO多路复用如果搭配阻塞IO来使用的话,由于
read()/write()/accept()都有可能阻塞当前线程,导致线程不能及时处理其他socket上的IO事件。
所以使用非阻塞IO的核心思想是避免阻塞在read()或write()或其他IO系统调用上,这样可以最大限度地复用thread-of-control,让一个线程可以处理多个socket连接。IO线程只能阻塞在IO多路复用函数上,在本项目中即阻塞在epoll_wait()上。
TCP Connection为什么需要Output Buffer?
考虑一个常见场景:应用程序想通过TCP发送100KB数据,但是在调用write()过程中,操作系统只接受了80KB(受TCP滑动窗口机制控制),如果使用阻塞IO的话,程序会阻塞在这里,直到操作系统接受剩余的20KB数据,但是肯定不能阻塞在这里等待,因为不知道要等多久(取决于对方什么时候接收数据,然后滑动TCP窗口),所以应该使用非阻塞IO(缓冲区满时返回EAGAIN,缓冲区空间不足时返回EWOULDBLOCK)来尽快返回到Event Loop,那么剩下的20KB呢?肯定不能丢掉,这时候就需要一个应用层缓冲区也就是Output Buffer来保管这20KB数据了,然后注册POLLOUT事件,一旦文件描述符变为可写就立即发送数据。当第二次也没能发完这20KB数据时,应该继续关注POLLOUT事件,而如果发完了则应该停止关注POLLOUT事件,以免发生Busy Loop。如果应用程序又想发送50KB数据呢?这时候Output Buffer里还有20KB数据,那么应该将这50KB数据追加到那20KB数据之后再一并发送。
TCP Connection为什么需要Input Buffer?
由于TCP是一个无边界的字节流协议,所以接收方必须要处理“一次接收到的数据不足以构成一条完整的消息”和“一次接收到的数据包含多条消息”等情况。考虑一个常见场景:发送方发送了两条1KB的消息(总共2KB),那么接收方接收到的数据可能有以下情况:
一次性收到2KB数据;
分两次收到:第一次600B,第二次1400B;
分两次收到:第一次1400B,第二次600B;
分两次收到:第一次1KB,第二次1KB;
分三次收到:第一次600B,第二次800B,第二次600B;
其他任何可能:一般而言,长度为n字节的消息分块到达的可能性有2n-1种。
也就是说必须要考虑数据不完整的情况,这时候就需要准备一个Input Buffer,先把socket中的数据读到Input Buffer中,等到足够构成一条完整的消息时再通知应用程序的业务处理逻辑。
Buffer的设计要点
Buffer对外表现为一块连续的内存,以方便用户代码的编写;
Buffer并不是固定大小的,其底层使用
std::vector<char>容器,所以Buffer的容量可以动态增长以适应不同长度的消息;Buffer的读写使用分散读、集中写,以减少系统调用的开销。
Buffer的分散读
在非阻塞网络编程中,我们一方面希望减少系统调用的次数,一次读的数据越多越划算,所以似乎应该准备一个足够大的缓冲区?但是另一方面我们又希望降低内存占用率,那么如何权衡呢?一个巧妙的方法是使用readv()和栈空间进行分散读,既减少了系统调用的次数,又在一定程度上降低了内存占用率。具体做法是在栈上申请一个65536字节的extrabuf,即iovec有两块,第一块指向Buffer中的vector,第二块则指向extrabuf,这样的话如果数据不多的话就全部读到vector中去了,而如果数据太大超过vector的容量时,则超出的数据会被读到extrabuf中,等到vector扩容后再追加到vector中。如此便解决了数据过大时需要多次read()调用的开销,因为总缓冲区足够大所以通常readv()一次系统调用就能读完,并且也避免了vector初始容量过大造成的内存浪费。
Buffer的集中写
在对HTTP Request进行响应时,HTTP Response报文由响应行、响应头和响应正文组成,其中响应行和响应正文在内存中,而响应正文通常为静态HTML资源文件,那么则需要将这两部分分散的数据集中写入到socket中去,本项目采用的方法是使用writev()和内存映射mmap(),同样有两块iovec,第一块指向响应行和响应正文,第二块指向HTML资源文件映射后的内存(如果响应体为空则用不上第二块),这样通常只需通过writev()一次系统调用就能将两部分数据写入socket。
使用YAML来配置运行参数
由于本项目中有多个运行参数需要配置,若是硬编码的话不够灵活,若是命令行传参的话又略显繁琐,最终决定使用YAML作为配置文件,其中YAML配置文件的解析引用了yaml-cpp库。对于配置项的读取,我想它应该是方便随用随取的,而由于配置只有也应该只有一份,Config 应该被设计为单例模式。
在多线程编程中,单例模式需要考虑线程安全问题,由于即时加载(饿汉模式)的单例模式本身就是线程安全的,故着重讨论惰性加载(懒汉模式)的单例模式。
线程不安全的单例模式
class Singleton {
inline static Singleton *instance_ = nullptr;
Singleton() = default;
~Singleton() = default;
public:
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *getInstance() {
if (instance_ == nullptr) {
instance_ = new Singleton();
}
return instance_;
}
};稍微有一点线程安全意识的读者应该都能发现,上面这个例子中的getInstance()明显不是线程安全的,原因是在判断if (instance == nullptr)时,可能有多个线程进入if块内,从而实例化多个对象,那么怎样保证其线程安全呢?有读者肯定会想到加锁,来看接下来的例子。
使用双重检查锁定
双重检查锁定(Double check locked, DCL)是Lazy-Initialize的单例模式中一种常见的设计方式,实现形式如下:
class Singleton {
inline static std::mutex mutex_;
inline static Singleton *instance_ = nullptr;
Singleton() = default;
~Singleton() = default;
public:
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *getInstance() {
if (instance_ == nullptr) {
std::lock_guard lock(mutex_);
if (instance_ == nullptr) {
instance_ = new Singleton();
}
}
return instance_;
}
};以上的代码看起来好像是线程安全的,但是其可能仍然存在安全隐患。instance_ = new Singleton();可以分解为三个步骤,内存分配、构造对象和赋值指针,而由于指令重排序的存在,那么指针赋值可能在发生在对象被完全构造之前,那么其他线程就有可能得到一个不为nullptr但是又没有完全被构造的instance_。那么如何保证内存序不被重排呢?答案是使用std::atomic。
使用std::atomic控制内存序
class Singleton {
inline static std::mutex mutex_;
inline static std::atomic<Singleton *> instance_ = nullptr;
Singleton() = default;
~Singleton() = default;
public:
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *getInstance() {
Singleton *tmp = instance_.load(std::memory_order_acquire);
if (tmp == nullptr) {
std::lock_guard lock(mutex_);
tmp = instance_.load(std::memory_order_relaxed);
if (tmp == nullptr) {
tmp = new Singleton();
instance_.store(tmp, std::memory_order_release);
}
}
return tmp;
}
};上面的方式虽然解决了问题,但是比较复杂,那有没有更好的方法呢?C++11引入了std::call_once和std::once_flag。
使用std::call_once和std::once_flag
class Singleton {
inline static std::once_flag flag_;
inline static Singleton *instance_ = nullptr;
Singleton() = default;
~Singleton() = default;
public:
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *getInstance() {
std::call_once(flag_, [] {
instance_ = new Singleton();
});
return instance_;
}
};可以看到代码简洁了不少,除此之外,C++11还支持了“魔法静态变量(Magic static)”,使用这个特性可以更简单方便地创建单例。
使用局部静态变量创建单例(推荐)
class Singleton {
Singleton() = default;
~Singleton() = default;
public:
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton &getInstance() {
static Singleton instance;
return instance;
}
};可以看到这是最简洁最方便的方式,C++11标准保证了函数内的静态局部变量的初始化是线程安全的,本项目中所有单例也都是使用这种方式。
懒加载的配置会影响性能吗?
本项目中Config虽然是懒加载的单例,但所有配置项的读取都发生在Server初始化时,故而当程序真正运行起来后不会因为需要读取配置而造成影响。
可能有读者会发现上面的例子中有一行这样的代码:inline static Singleton *instance_ = nullptr; 关于inline关键字的作用,可以移步我这篇博文:
HTTP Request报文的解析
HTTP Request报文的结构
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式:
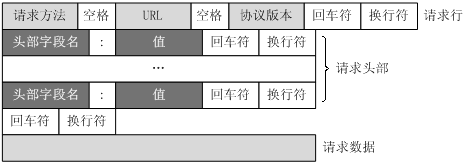
请求行(Request Line):
方法:如 GET、POST、PUT、DELETE等,指定要执行的操作。
请求 URI(统一资源标识符):请求的资源路径,通常包括主机名、端口号(如果非默认)、路径和查询字符串。
HTTP 版本:如 HTTP/1.1 或 HTTP/2。
请求行的格式示例:
GET /index.html HTTP/1.1请求头(Request Headers):
包含了客户端环境信息、请求体的大小(如果有)、客户端支持的压缩类型等。
常见的请求头包括
Host、User-Agent、Accept、Accept-Encoding、Content-Length等。
空行:
请求头和请求体之间的分隔符,表示请求头的结束。
请求体(可选):
在某些类型的HTTP请求(如 POST 和 PUT)中,请求体包含要发送给服务器的数据。
使用有限状态机解析请求报文
// 状态集
enum class ParseState {
ParseLine,
ParseHeaders,
ParseContent,
ParseFinish
};
// 解析状态机
bool HttpRequest::parse(Buffer &buff) {
static constexpr char END[] = "\r\n";
// 没有可读的字节
if (buff.readableSize() == 0) {
LOGW << "buff.readableSize() == 0";
return false;
}
// 读取数据开始
while (buff.readableSize() && state_ != ParseState::ParseFinish) {
// 从 buff 中取出待读取的数据并去除 "\r\n",返回有效数据的行末指针
const char *lineEnd = std::search(buff.peek(), const_cast<const Buffer &>(buff).beginWrite(), END, END + 2);
std::string line(buff.peek(), lineEnd);
switch (state_) {
case ParseState::ParseLine:
LOGD << "parseRequestLine(line): " << line;
if (!parseRequestLine(line)) {
LOGW << "parseRequestLine(line) failed";
return false;
}
state_ = ParseState::ParseHeaders;
break;
case ParseState::ParseHeaders:
LOGD << "parseHeaders(line): " << line;
if (!parseHeaders(line)) {
state_ = ParseState::ParseContent;
}
break;
case ParseState::ParseContent:
LOGD << "parseContent(line): " << line;
parseContent(line);
state_ = ParseState::ParseFinish;
break;
default:
break;
}
// 读完了
if (lineEnd == buff.beginWrite()) {
buff.retrieveAll();
break;
}
// 跳过 "\r\n"
buff.retrieveUntil(lineEnd + 2);
}
LOGD << "[" << METHOD_STR.at(method_) << "], [" << path_.c_str() << "], [" << VERSION_STR.at(version_) << "]";
return true;
}构造HTTP Response报文
HTTP Response报文的结构
HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
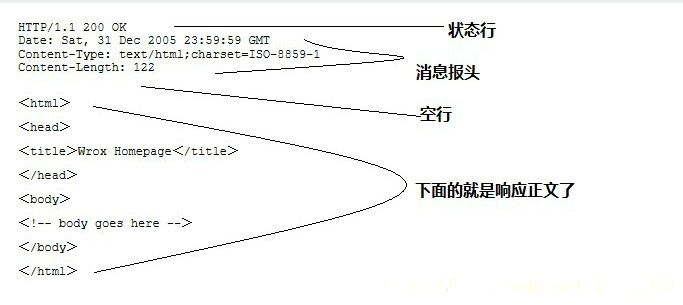
状态行(Status Line):
HTTP 版本:与请求消息中的版本相匹配。
状态码:三位数,表示请求的处理结果,如 200 表示成功,404 表示未找到资源。
状态信息:状态码的简短描述。
状态行的格式示例:
HTTP/1.1 200 OK响应头(Response Headers):
包含了服务器环境信息、响应体的大小、服务器支持的压缩类型等。
常见的响应头包括
Content-Type、Content-Length、Server、Set-Cookie等。
空行:
响应头和响应体之间的分隔符,表示响应头的结束。
响应体(可选):
包含服务器返回的数据,如请求的网页内容、图片、JSON数据等。
日志库的设计
在服务端编程中,日志是必不可少的,当进行故障诊断与排查时,详细的日志往往是最有效的信息。
2024-10-14 01:16:46.916118 14745 I: Client[6][127.0.0.1:18579] has connected, connection count:1 - HttpConnection.cpp:34本日志库的一条完整的日志包含以下信息:
微秒级时间戳,用于检查日志记录的精确时刻;
发出此条日志消息的线程ID,可用于检查死锁等;
此条日志的级别,方便过滤不同级别的日志;
日志消息正文;
发出此日志的位置文件和行数,方便定位源代码。
本日志库大体可分为前端和后端两个部分。前端是供应用程序使用的接口,并生成日志消息;后端则是负责将日志消息写入到目的地。
日志库前端的设计
C++日志库的前端API大体上有两种风格:
C/Java的
printf(fmt, ...)风格;C++的
stream << ...风格。
本日志库采用的是第二种风格,这样用起来更自然,也不必费心考虑字符串格式化和参数类型,可以随用随写。另一个好处是当输出的日志级别高于语句的的日志级别时,打印日志是个空操作,运行时开销接近于零。例如当日志级别设置为WARNING时,LOGI << getMessage()就是空操作,根本不会调用getMessage()函数,而使用printf风格的话则不容易做到这一点。其中LOGI的宏定义如下:
#define LOGI \
if (Logger::logLevel() <= LogLevel::Info) \
Logger(__FILE_NAME__, __LINE__, LogLevel::Info).logStream()出于性能的考虑,本日志库也没有使用标准库的iostream,而是另外封装了class LogStream,其中重载了常用数据类型的输出流运算符。并且为了方便必要的时候进行字符串格式化控制,还实现了class Fmt辅助类。
日志库后端的设计
后端采用双缓冲(double-buffering)技术,基本思路是准备两块buffer:A和B,前端负责将日志消息写入buffer A,后端负责将buffer B中的内容写入文件。当buffer A写满后,交换A和B,让后端将buffer A中的消息写入文件,而前端则继续往buffer B中写入消息,如此往复。用两个buffer的好处是新建一条日志消息的时候不必等待磁盘文件操作,也避免每条日志消息都唤醒后端线程。换言之,前端不是将日志消息一条条传给后端,而是将很多条消息组成一个大的buffer再整个传给后端,这样就减少了线程唤醒的频率,降低了开销。另外,为了及时将日志写入文件,即时buffer A未满,日志库也会每3秒执行一次上述交换写入文件的操作。
实际实现采用了四块缓冲,这样可以进一步减少或避免日志库前端的等待。数据结构如下:
using LogBuffer = FixedBuffer<LargeBufferSize>;
using BufferVector = std::vector<std::unique_ptr<LogBuffer> >;
using BufferPtr = BufferVector::value_type;
std::mutex mutex_;
std::condition_variable cvBuffersEmpty_;
// 当前正在写入日志的缓冲区
BufferPtr currentBuffer_;
// 预备缓冲区
BufferPtr nextBuffer_;
// 已经写满的待同步到磁盘的缓冲区列表
BufferVector buffers_;先看发送方发送一条日志的回调函数实现:
void AsyncLogging::append(const char *logLine, const size_t len) {
std::lock_guard lock(mutex_);
if (currentBuffer_->writableBytes() > len) {
// 如果当前工作缓冲区还没有写满,则直接追加到当前工作缓冲区
currentBuffer_->append(logLine, len);
} else {
// 否则将当前工作缓冲区送入 buffers,以待同步到磁盘
buffers_.push_back(std::move(currentBuffer_));
// 尝试将预备缓冲区用作当前工作缓冲区
if (nextBuffer_) {
// 如果存在空闲的预备缓冲区,则将该预备缓冲区用作当前工作缓冲区
currentBuffer_ = std::move(nextBuffer_);
} else {
// 如果前端写日志的速率太快,导致预备缓冲区也被用完了,则新分配一块缓冲区作为当前工作缓冲区(实际应用中极少出现此种情况)
currentBuffer_ = std::make_unique<LogBuffer>();
}
// 将日志追加到新设置的当前工作缓冲区
currentBuffer_->append(logLine, len);
// 唤醒后端线程将 buffers 中的缓冲区同步到磁盘
cvBuffersEmpty_.notify_one();
}
}再看接收方(后端)线程函数的实现,此处仅给出临界区内关键代码,其他细节详询源文件:
void AsyncLogging::threadCallback() {
// ...
// 预分配两块 buffer,以备在临界区内交换
BufferPtr newBuffer1(new LogBuffer);
BufferPtr newBuffer2(new LogBuffer);
// ...
while (running_) {
assert(newBuffer1);
assert(newBuffer2);
assert(buffersToWrite.empty());
{
std::unique_lock lock(mutex_);
if (buffers_.empty()) {
// 当 buffers 里没有待同步到磁盘的缓冲区时,等待条件的发生或者超时 flushInterval_
cvBuffersEmpty_.wait_for(lock, std::chrono::seconds(flushInterval_), [&] {
return !buffers_.empty();
});
}
// 条件发生时,将当前工作缓冲区送入 buffers 以待同步到磁盘,目的是哪怕前端在 3s 内没有写满一块缓冲区,也能及时将日志同步到磁盘
buffers_.push_back(std::move(currentBuffer_));
// 将预分配的空闲缓冲区用作当前工作缓冲区
currentBuffer_ = std::move(newBuffer1);
// 直接把 buffers 里的缓冲区都拿过来,以便后续安全地访问,避免临界区过长或在访问 buffers 的时候 buffers 又被前端改变
buffersToWrite.swap(buffers_);
if (!nextBuffer_) {
// 如果预备缓冲区也用完了,则将另一块预分配的缓冲区用作预备缓冲区,保证前端始终有一个预备缓冲区可随时取用
nextBuffer_ = std::move(newBuffer2);
}
}
// ... write and flush
}
// ... flush
}利用RAII机制实现数据库连接池
RAII,全称资源获取即初始化(英语:Resource Acquisition Is Initialization),它是在一些面向对象语言中的一种惯用法。
RAII要求,资源的有效期与持有资源的对象的生命期严格绑定,即由对象的构造函数完成资源的分配(获取),同时由析构函数完成资源的释放。在这种要求下,只要对象能正确地析构,就不会出现资源泄漏问题。
// 自定义删除器,用于确保连接被正确关闭
struct MysqlDeleter {
void operator()(MYSQL *conn) const {
if (conn) {
mysql_close(conn);
LOGD << "MySQL connection closed";
}
}
};
using MysqlPtr = std::unique_ptr<MYSQL, MysqlDeleter>;
class SqlConnPool {
// RAII 连接包装类
class Connection {
MYSQL *conn_;
SqlConnPool &pool_;
bool moved_ = false;
public:
Connection(MYSQL *conn, SqlConnPool &pool) :
conn_(conn),
pool_(pool) {
}
// 析构时释放连接
~Connection() {
if (conn_ && !moved_) {
pool_.releaseConnection(conn_);
}
}
// 禁止拷贝
Connection(const Connection &) = delete;
Connection &operator=(const Connection &) = delete;
// 移动构造
Connection(Connection &&other) noexcept:
conn_(other.conn_),
pool_(other.pool_),
moved_(other.moved_) {
other.conn_ = nullptr;
other.moved_ = true;
}
// 移动赋值
Connection &operator=(Connection &&other) noexcept {
if (this != &other) {
if (conn_ && !moved_) {
pool_.releaseConnection(conn_);
}
conn_ = other.conn_;
moved_ = other.moved_;
other.conn_ = nullptr;
other.moved_ = true;
}
return *this;
}
// 允许转换为 MYSQL * 类型
explicit operator MYSQL *() const {
return conn_;
}
[[nodiscard]]
MYSQL *get() const {
return conn_;
}
};
// 可用连接队列
std::queue<MYSQL *> connQue_;
// 使用中的连接指针列表
std::list<MYSQL *> usedConn_;
// 连接池读写锁
mutable std::shared_mutex poolMutex_;
// 条件变量,使用 condition_variable_any 以配合 shared_mutex
std::condition_variable_any cond_;
// 监控线程
std::thread monitorThread_;
bool shutdown_ = false;
// 数据库连接信息
std::string host_;
uint16_t port_;
std::string user_;
std::string pwd_;
std::string dbName_;
// 连接池大小控制
int minPoolSize_;
int maxPoolSize_;
// 当前连接池大小
int currentPoolSize_{};
// 空闲可用的连接数量
int availableConnections_{};
SqlConnPool();
// 创建一个新的 MySQL 连接
MysqlPtr createConnection() const;
Connection _getConnection();
// 释放连接(仅供Connection类调用)
void releaseConnection(MYSQL *conn);
// 确保数据库存在,如果不存在则创建
bool ensureDatabase() const;
// 监控连接池,动态扩展和收缩,并进行健康检查
void monitorPool();
public:
// 禁止拷贝和赋值
SqlConnPool(const SqlConnPool &) = delete;
SqlConnPool &operator=(const SqlConnPool &) = delete;
// 销毁连接池
~SqlConnPool();
// 获取连接(返回 Connection 对象)
static Connection getConnection() {
static SqlConnPool sqlConnPool;
LOGD << "SqlConnPool::getConnection()";
return sqlConnPool._getConnection();
}
};线程池的设计
请移步我的以下两篇博文:
时间堆的设计
为了防止长连接既不活跃又长时间占用服务器资源,我们需要实现一个超时断开连接的操作,于是使用小根堆这一数据结构来管理,当某个连接在指定时间内没有任何操作则执行断开连接的回调,否则刷新超时时间。
堆(Heap)是一种常用的数据结构,特别适用于实现优先队列等功能。当堆用于管理基于时间的事件(如定时任务、事件调度等)时,通常被称为时间堆。然而,堆的一个限制是,对于堆中任意元素的查找操作(如查找、删除或更新某个特定元素)可能需要线性的时间复杂度 O(n),因为堆本身并不支持快速查找。为了解决这一问题,本项目中使用哈希表(Hash Table)辅助时间堆的查找操作,使其查找操作的时间复杂度降为常数O(1)。
using TimeoutCallback = std::function<void()>;
using Clock = std::chrono::system_clock;
using TimePoint = std::chrono::system_clock::time_point;
struct TimerNode {
uint64_t id;
// 超时时间点
TimePoint expiration;
// 超时回调function<void()>
TimeoutCallback timeoutCallback;
// 重载三路比较运算符(C++20起)可以同时默认实现 > < >= <= == != 六种基本比较运算符,减少代码冗余
// 三路比较运算符(C++20起)可以返回三种类型:
// std::strong_ordering:强序,严格的顺序比较。隐含可替换关系,若 a 等价于 b,则 f(a) 等价于 f(b)
// 若 a 小于 b,返回 std::strong_ordering::less
// 若 a 大于 b,返回 std::strong_ordering::greater
// 若 a 等于 b,返回 std::strong_ordering::equal
// std::weak_ordering:弱序,允许等价但不严格的顺序比较。不隐含可替换关系,若 a 等价于 b,则 f(a) 不一定等价于 f(b)
// 若 a 小于 b,返回 std::weak_ordering::less
// 若 a 大于 b,返回 std::weak_ordering::greater
// 若 a 等价于 b,返回 std::weak_ordering::equivalent
// std::partial_ordering:偏序,允许部分顺序比较。既不隐含可替换关系,也允许完全不可比较关系
// 若 a 小于 b,返回 std::partial_ordering::less
// 若 a 大于 b,返回 std::partial_ordering::greater
// 若 a 等价于 b,返回 std::partial_ordering::equivalent
// 否则,返回 std::partial_ordering::unordered
// 此处两个 std::chrono::system_clock::time_point 类型比较的返回值应为 std::strong_ordering
auto operator<=>(const TimerNode &t) const {
return expiration <=> t.expiration;
}
};参考&致谢
《Linux多线程服务端编程》 - 陈硕